Hi there, this is Eugenio! I work on advancing robot learning and foundation models for manipulation. Currently, I am a Research Engineer at Flexion Robotics, where I had the unique opportunity to build our manipulation efforts from the ground up as the team's first hire. Before Flexion, I earned a PhD at the University of Freiburg, Germany, under the supervision of Prof. Abhinav Valada and Prof. Wolfram Burgard. My research focused on Imitation and Interactive Learning for robotic manipulation. Before my PhD, I contributed to ambitious engineering projects. In particular, I worked as Trajectory and Vehicle Dynamics Control Engineer at AMZ Driverless, ETH's Formula Student Driverless team, and interned at ANYbotics AG as Robotics Software Engineer in the autonomous navigation team. I am also interested in the world of startups and product. In summer 2023, I had the fortune to work at Google as APM intern.
Language-conditioned robotic policies allow users to specify tasks using natural language. While much research has focused on improving the action prediction of language- conditioned policies, reasoning about task descriptions has been largely overlooked. Ambiguous task descriptions often lead to downstream policy failures due to misinterpretation by the robotic agent. To address this challenge, we introduce AmbResVLM, a novel method that grounds language goals in the observed scene and explicitly reasons about task ambiguity. We extensively evaluate its effectiveness in both simulated and real- world domains, demonstrating superior task ambiguity detection and resolution compared to recent state-of-the-art methods. Finally, real robot experiments show that our model improves the performance of downstream robot policies, increasing the average success rate from 69.6% to 97.1%. We make the data, code, and trained models publicly available at https://ambres.cs.uni-freiburg.de.
IROS 2025 paperLearning from expert demonstrations is a promising approach for training robotic manipulation policies from limited data. However, imitation learning algorithms require a number of design choices ranging from the input modality, training objective, and 6-DoF end-effector pose representation. Diffusion- based methods have gained popularity as they enable predicting long-horizon trajectories and handle multimodal action distributions. Recently, Conditional Flow Matching (CFM) (or Rectified Flow) has been proposed as a more flexible generalization of diffusion models. In this paper, we investigate the application of CFM in the context of robotic policy learning and specifically study the interplay with the other design choices required to build an imitation learning algorithm. We show that CFM gives the best performance when combined with point cloud input observations. Additionally, we study the feasibility of a CFM formulation on the SO(3) manifold and evaluate its suitability with a simplified example. We perform extensive experiments on RLBench which demonstrate that our proposed PointFlowMatch approach achieves a state-of-the-art average success rate of 67.8% over eight tasks, double the performance of the next best method. We make the code and trained models publicly available at https://pointflowmatch.cs.uni-freiburg.de.
CoRL 2024 paper
Reliable object grasping is a crucial capability for autonomous robots. However, many existing grasping approaches focus on general clutter removal without explicitly modeling objects and thus only relying on the visible local geometry. We introduce CenterGrasp, a novel framework that combines object awareness and holistic grasping. CenterGrasp learns a general object prior by encoding shapes and valid grasps in a continuous latent space. It consists of an RGB-D image encoder that leverages recent advances to detect objects and infer their pose and latent code, and a decoder to predict shape and grasps for each object in the scene. We perform extensive experiments on simulated as well as real-world cluttered scenes and demonstrate strong scene reconstruction and 6-DoF grasp-pose estimation performance. Compared to the state of the art, CenterGrasp achieves an improvement of 38.5 mm in shape reconstruction and 33 percentage points on average in grasp success. We make the code and trained models publicly available at https://centergrasp.cs.uni-freiburg.de.

Learning to solve complex manipulation tasks from visual observations is a dominant challenge for real-world robot learning. Deep reinforcement learning algorithms have recently demonstrated impressive results, although they still require an impractical amount of time-consuming trial-and-error iterations. In this work, we consider the promising alternative paradigm of interactive learning where a human teacher provides feedback to the policy during execution, as opposed to imitation learning where a pre-collected dataset of perfect demonstrations is used. Our proposed CEILing (Corrective and Evaluative Interactive Learning) framework combines both corrective and evaluative feedback from the teacher to train a stochastic policy in an asynchronous manner, and employs a dedicated mechanism to trade off human corrections with the robot’s own experience. We present results obtained with our framework in extensive simulation and real-world experiments that demonstrate that CEILing can effectively solve complex robot manipulation tasks directly from raw images in less than one hour of real-world training.
The goal of this thesis project was to tackle the autonomous racing problem using state of the art reinforcement learning algorithms to learn an optimal policy from scratch. In order to overcome model mismatch, also known as reality gap, I applied on the simulation the well known model randomization and a novel policy regularization strategy. The policy is then refined by training on the physical car and the achieved performance is comparable to that achieved previously by a model based controller.
ICRA 2021 paper
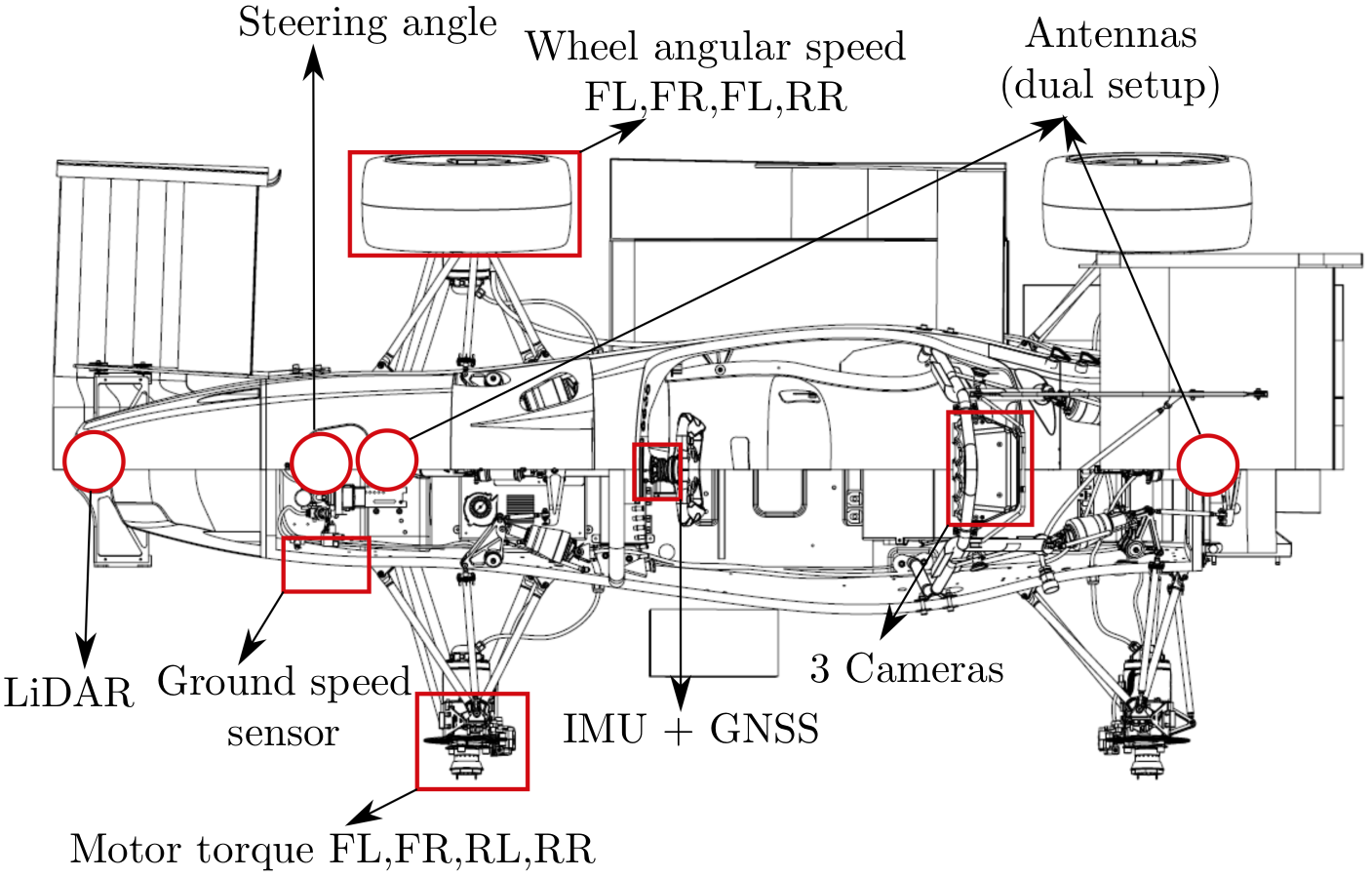
AMZ Racing is one of the world's leading Formula Student teams, and the team behind the world's fastest accelerating electric vehicle. Each year two new teams of students are formed: the Electric team sets out to design, manufacture, test and race the fastest electric race car, while the Driverless team transforms the car from the previous year in an autonomous machine. The AMZ Driverless Team needs to tackle different challenges in order to build a fast autonomous race car: perception, velocity estimation, SLAM, sensor synchronization, motion planning, vehicle control, continuous integration, data management, safety systems, computing hardware.
I was responsible for the control and motion planning algorithms: I used the Delaunay triangulation to discretize the search space, applied beam search to find candidate paths and a cost function to evaluate them. Our tireless work resulted in an autonomous race car capable of securing the overall first place at each competition we participated in.
JFR 2020 Paper